Second Chapter
向量
(a)接口与实现
抽象数据结构:
数据结构:
我们做一个比喻。把数据结构比喻成汽车,和这个汽车相关的有两类人,一类是用户,他们不关心汽车内部细节,他们只使用汽车;另一类人是汽车产品的设计者和实现者。他们关心内容是不同的,对用户而言,他们只关心产品的特性和功能。而实现者则需要对这些功能和特性具体如何落实负责。
任何一个数据结构初始化的时候都是不包括任何任何实质的内容。
typedef int rank; // 使用int代替秩的概念
参考C++书306页,PKU
//补充C++语言中函数模版的知识
//函数模版的定义方法
template <class 类型参数1,class 类型参数2,...>
返回值类型 模版名 (形参名)
{
函数体
};
template <class T>
void Swap(T &x,T &y){
T temp = x;
x = y;
y = temp;
}
//其中class的关键字也可以用typename替换。
//类模版定义方法
template <类型参数表>
class 类模版名
{
成员函数和成员变量
};
类型参数表的写法是:class 类型参数1,class 类型参数2,...
类模版中的成员函数,在类模版定义外面编写时的语法如下:
template <类型参数表>
返回值类型 类模版名<类型参数名列表>::成员函数名(参数表)
{
...
}
C++语言支持模版,有了模版,就可以只编写一个swap,编译器会根据swap模版,自动生成多个swap函数,用以交换不同类型的变量。C++中,模版分为函数模版和类模版两种。函数模版是用于生成函数的,类模版则是用于生成类的。
构造和析构

注意点:
这门课程里,rank称为秩。
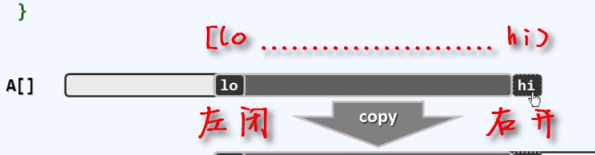
我们描述一个区间的时候,往往采用左闭右开的形式。
- 这里的上溢(overflow)是指空间不够。下溢(underflow)是指空间利用率低下,空间浪费。
(b)可扩充向量
动态空间管理
课程问题:
是否可以将视频里向量扩容代码中的:
for (int i = 0; i < _size; i++) _elem[i] = oldElem[i];
替代为:
memcpy(_elem, oldElem, _size * sizeof(T));
否,因为后者能否达到目的与元素类型T有关
当T为非基本类型且有对应的赋值运算符以执行深复制时,前一段代码会调用赋值运算符,而后一段只能进行浅复制。
递增扩容分摊到每次扩容上的时间为O(n). 加倍式扩容分摊到每次扩容上的时间为O(1).
分摊复杂度

(c)无序向量
quiz
 补充C++中重载知识:(C++210页)
补充C++中重载知识:(C++210页)
运算符重载,实质上是编写以运算符作为名称的函数。不妨把这样的函数成为运算符函数。
运算符函数的格式如下:
返回值类型 operator 运算发 (形参表)
{
...
}
eg.
Complex operator + (const Complex & a, const Complex & b)
{
return Complex(a.real + b.real,a,imag + b.imag);
}
插入和区间删除
插入的时候元素要从后向后移动,区间删除的时候元素要从前向前移动。 之所以这么做的原因都是为了避免元素被覆盖。
单元素的删除是基于区间删除来实现的。因为表示一个区间的时候,使用的规则是左闭右开,所以假设这里删除[r],实际上可以看作是删除区间[r,r+1).
唯一化
使得每一组元素中,重复的元素只保留一个拷贝
思路: 在秩为1的位置开始,和前面的元素做比较,如果相同,就把当前元素,即秩为1 的元素删除,如果不相同,秩的值+1.
我们通过不变性和单调性(算法总会执行结束)来证明这个算法是正确的。
遍历
遍历有两种思路来实现:(1)函数指针。(2)函数对象
 给出函数对象的实现:
给出函数对象的实现:

补充知识
篇一、函数指针
函数指针:是指向函数的指针变量,在C编译时,每一个函数都有一个入口地址,那么这个指向这个函数的函数指针便指向这个地址。
函数指针的用途是很大的,主要有两个作用:用作调用函数和做函数的参数。
函数指针的声明方法:
数据类型标志符 (指针变量名) (形参列表);
一般函数的声明为:
int func ( int x );
而一个函数指针的声明方法为:
int (*func) (int x);
前面的那个(*func)中括号是必要的,这会告诉编译器我们声明的是函数指针而不是声明一个具有返回型为指针的函数,后面的形参要视这个函数指针所指向的函数形参而定。
然而这样声明我们有时觉得非常繁琐,于是typedef可以派上用场了,我们也可以这样声明:
typedef int (*PF) (int x);
PF pf;
这样pf便是一个函数指针,方便了许多。当要使用函数指针来调用函数时,func(x)或者 (*fucn)(x) 就可以了,当然,函数指针也可以指向被重载的函数,编译器会为我们区分这些重载的函数从而使函数指针指向正确的函数。
例子:
typedef void (*PFT) ( char ,int );
void bar(char ch, int i)
{
cout<<"bar "<<ch<<' '<<i<<endl;
return ;
}
PFT pft;
pft = bar;
pft('e',91);
例子中函数指针pft指向了一个已经声明的函数bar(),然后通过pft来实现输出字符和整型的目的。 函数指针另一个作用便是作为函数的参数,我们可以在一个函数的形参列表中传入一个函数指针,然后便可以在这个函数中使用这个函数指针所指向的函数,这样便可以使程序变得更加清晰和简洁,而且这种用途技巧可以帮助我们解决很多棘手的问题,使用很小的代价就可获得足够大的利益(速度+复杂度)。
typedef void (*PFT) ( char ,int );
void bar(char ch, int i)
{
cout<<"bar "<<ch<<' '<<i<<endl;
return ;
}
void foo(char ch, int i, PFT pf)
{
pf(ch,i);
return ;
}
PFT pft;
pft = bar;
foo('e',12,pft);
上述例子我们首先利用一个函数指针pft指向bar(),然后在foo()函数中使用pft指针来调用bar(),实现目的。将这个特点稍加利用,我们就可以构造出强大的程序,只需要同样的foo函数便可以实现对不同bar函数的调用。
篇二、函数对象
前面是函数指针的应用,从一般的函数回调意义上来说,函数对象和函数指针是相同的,但是函数对象却具有许多函数指针不具有的有点,函数对象使程序设计更加灵活,而且能够实现函数的内联(inline)调用,使整个程序实现性能加速。
函数对象:这里已经说明了这是一个对象,而且实际上只是这个对象具有的函数的某些功能,我们才称之为函数对象,意义很贴切,如果一个对象具有了某个函数的功能,我们变可以称之为函数对象。 如何使对象具有函数功能呢,很简单,只需要为这个对象的操作符()进行重载就可以了,如下:
class A{
public:
int operator()(int x){return x;}
};
A a;
a(5);
这样a就成为一个函数对象,当我们执行a(5)时,实际上就是利用了重载符号()。 函数对象既然是一个“类对象”,那么我们当然可以在函数形参列表中调用它,它完全可以取代函数指针!如果说指针是C的标志,类是C++特有的,那么我们也可以说指针函数和函数对象之间的关系也是同前者一样的!(虽然有些严密)。当我们想在形参列表中调用某个函数时,可以先声明一个具有这种函数功能的函数对象,然后在形参中使用这个对象,他所作的功能和函数指针所作的功能是相同的,而且更加安全。 下面是一个例子:
class Func{
public:
int operator() (int a, int b)
{
cout<<a<<'+'<<b<<'='<<a+b<<endl;
return a;
}
};
int addFunc(int a, int b, Func& func)
{
func(a,b);
return a;
}
Func func;
addFunc(1,3,func);
上述例子中首先定义了一个函数对象类,并重载了()操作符,目的是使前两个参数相加并输出,然后在addFunc中的形参列表中使用这个类对象,从而实现两数相加的功能。 如果运用泛型思维来考虑,可以定一个函数模板类,来实现一般类型的数据的相加:
class FuncT{
public:
template<typename T>
T operator() (T t1, T t2)
{
cout<<t1<<'+'<<t2<<'='<<t1+t2<<endl;
return t1;
}
};
template <typename T>
T addFuncT(T t1, T t2, FuncT& funct)
{
funct(t1,t2);
return t1;
}
FuncT funct;
addFuncT(2,4,funct);
addFuncT(1.4,2.3,funct);
大名鼎鼎的STL中便广泛的运用了这项技术,详细内容可参见候捷大师的一些泛型技术的书籍,不要以为函数对象的频繁调用会使程序性能大大折扣,大量事实和实验证明,正确使用函数对象的程序要比其他程序性能快很多!所以掌握并熟练运用函数对象才能为我们的程序加分,否则....... 如此看来,函数对象又为C++敞开了一道天窗,但随之而来的便是一些复杂的问题和陷阱,如何去蔽扬利还需要我们不断学习和探索。
(d1)有序向量:唯一化
无序向量:能够比较元素之间是不是相等。
有序向量:能够比较元素之间谁打谁小。
一个向量是有序的,当且仅当调用disordered()函数后,返回值是0;disordered()函数的返回结果是一共有多少对紧邻逆序对。
在唯一化的时候,我们较少了两种算法思想:第一种:相邻比较,如果重复,就把后一个元素进行显示删除,时间复杂度是O(n平方)。第二种:维持两个指针,i和j,分别指向不同的元素,j一直向后移动,只有当遇到和i不一样的元素的时候才停下来。并且将j所指向的元素一次性向前移动。这个算法的复杂度是O(n).
(d2)有序向量:二分查找
有序向量的查找算法
注意点:我们给出的区间同样是左闭右开。
语义上的约定是很有必要的,否则我们所实现的接口,只能被孤立地利用,而不能成为一个可供广泛使用的部件,去提供给其他的算法利用。
讲一个ADS(抽象数据结构)的时候,从作用讲开去,然后一个约定,即外部接口,然后讲原理和实现。
编程习惯中使用“<”,因为<是和数轴上面从左到右的顺序一致的。一个数小于一个数就表明这个数在另外一个数的左侧。

使用二分查找,无论是查找成功还是查找失败,最后的时间复杂度是O(1.5*logn)

d(3)有序向量:Fibonacci查找
因为在查找的时候,向左和向右的成本是不一样的。向左只需要比较一次,向右需要比较两次。所以,我们为什么不把这棵搜索树做成左边的深度大于右边的深度呢!
如图:
 如果我们不改变算法的整体模式和框架,不难发现,Fibonacci search 的代码在实现上和之前的Binary Search 是几乎一样的。唯一的区别在于取mi的时候,如果是按照二分找,那么就是Binary search,如果是按照Fibonacci的方法找,那么就是Fibonacci search。
如果我们不改变算法的整体模式和框架,不难发现,Fibonacci search 的代码在实现上和之前的Binary Search 是几乎一样的。唯一的区别在于取mi的时候,如果是按照二分找,那么就是Binary search,如果是按照Fibonacci的方法找,那么就是Fibonacci search。
d(4)有序向量:二分查找(改进)
版本B改进思路:
版本B的实现结果是,每次迭代仅做一次关键码的比较。因此,所有分支就只有两个方向,而不再是三个。这样做导致的一个结果就是,不会存在一次命中的情况,想要命中某个元素的时候,必须得等到元素数目是1的时候,才能判断是否命中。
语义约定
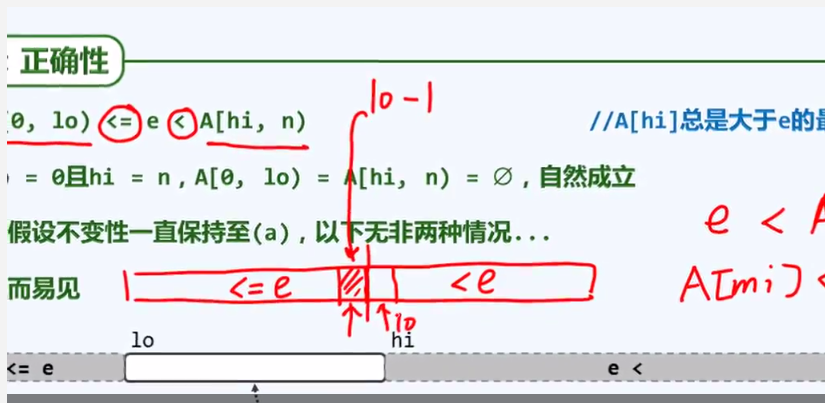
我们此前所说的所有Binary search和Fibonacci search都没有实现search()接口的语义约定:需要返回不大于e的最后一个元素。只有实现这一约定,才可有效支持算法。

版本C实现
 算法运行到最后的,hi-lo的宽度不断压缩压缩,最后缩小到一个等于0的区间。而这个宽度为0 的区间,与其说这是一个区间,不如说这是一个分界,他严格的将这个区间分成了左右两部分,左侧的部分是不大于e,而右侧的部分是严格地大于e。所以这个时候,我们只要返回左侧这个区间的最右端的那个元素就可以了。这个元素在最后那个瞬间,应该是等于lo-1.因为他的邻居才是这个时候的lo。
算法运行到最后的,hi-lo的宽度不断压缩压缩,最后缩小到一个等于0的区间。而这个宽度为0 的区间,与其说这是一个区间,不如说这是一个分界,他严格的将这个区间分成了左右两部分,左侧的部分是不大于e,而右侧的部分是严格地大于e。所以这个时候,我们只要返回左侧这个区间的最右端的那个元素就可以了。这个元素在最后那个瞬间,应该是等于lo-1.因为他的邻居才是这个时候的lo。
 Quiz:
Quiz:

(d5)有序向量:插值查找
interpolation search 可以做到复杂度是(loglogn)
(e)起泡排序
起泡排序中,我们可以针对常规的起泡排序做出两种不同程度的优化。
第一种:我们设置一个标记量,每次排序前,把这个标记设为true,每次两两比较的时候,如果发生了相邻逆序对的交换,我们就把标记设为false。直到有一次,走完一趟没有发生相邻逆序对的交换,我们则认为这个排序已经有序,结束排序工作。
第二种:排序过程中,如果局部存在一段序列是有序的,我们直接跳过这段有序的序列,减少排序次数。同时,如果发现该段序列已经是有序的,我们同样要提前结束排序工作。
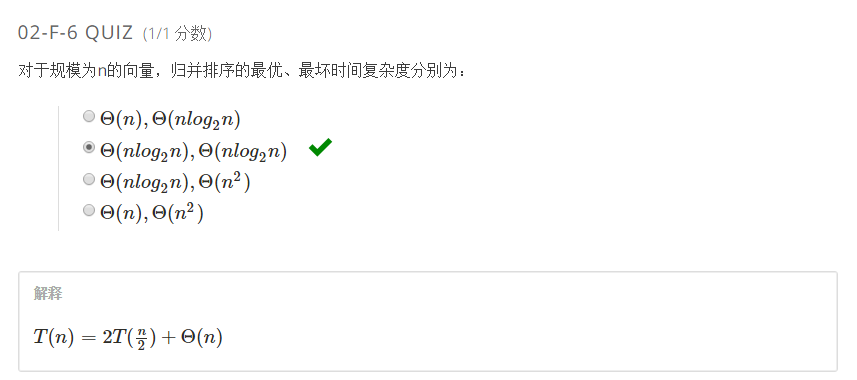
(f)归并排序
递归地进行分而治之然后再合并。
- (1)像所有的递归程序一样,第一步是处理递归基。
- (2)分,分而治之,分为左部和右部。
- (3)合并,merge。这里是关键。
归并排序的时间复杂度不受每个子序列的长度限制